Visualizing the flow of data

Transcription Data: The Importance of Creating Great, Reusable, Data
All transcription is data creation.
But not all data is equal.
Some data is messy, ambiguous, and unclear.
Some data is well formed, well structured, and unambiguous.
All data creation involves the identification of data types.
Declaring data types is what we mean when we say we are "encoding" a text.
But there are different ways of encoding a text, and each method has pros and cons.
Types of Encoding
Visual Encoding and Semantic Encoding.
Visual Encoding (VE)
- VE is what most traditional editors are familiar with.
- VE declares data types through visual differentiation.
- A title is differentiated from a regular text through italic rendering.
- A paragraph usually begins with an indentation represented through extra white space at the beginning of a line.
- A header is usually centered on the page, slightly larger, and surrounded by extra white space.
Example of Visual Encoding

The cons of visual encoding
While visual encoding may initially seem more intuitive and more pleasing to an editor, it has TWO fundamental problems.
First Problem: It is consistently ambiguous about the identification of datatypes
For example consider the various uses of italic rendering in a critical edition.

Second Problem: It fuses form and matter, making data type recognition inseparable from its original material representation.
Consider a heading is identified by its position in the center of a page surrounded by whitespace. If this rendering were lost, its distinction from the surrounding text would be lost.
This makes the dream of creating multiple representations (such as print and web displays) from a **Single Source Document** impossible.
Our aim must be to de-couple form and matter so that we can take that content and instantiate it in as many different types of matter (or media) as we wish.
Semantic Encoding (SE)
The better alternative is semantic encoding.
Instead of distinguish data types by how they appear, we explicit label data types using an agreed upon field standard vocabulary
If the data is a heading then let's call it a heading.
If the data is a title let's call it a title.
Simple Example of Semantic Encoding
Corpus Data: A data model to organize and relate all this transcription data
Consider the enormous variation data required to comprehensively describe a critical text
For example:
- The whole text
- Main subdivisions
- Witnesses to the text and its parts
- Transcriptions of individual witnesses
- Transcriptions of critical text built from transcriptions of individual witnesses
Such a list only scratches the surface

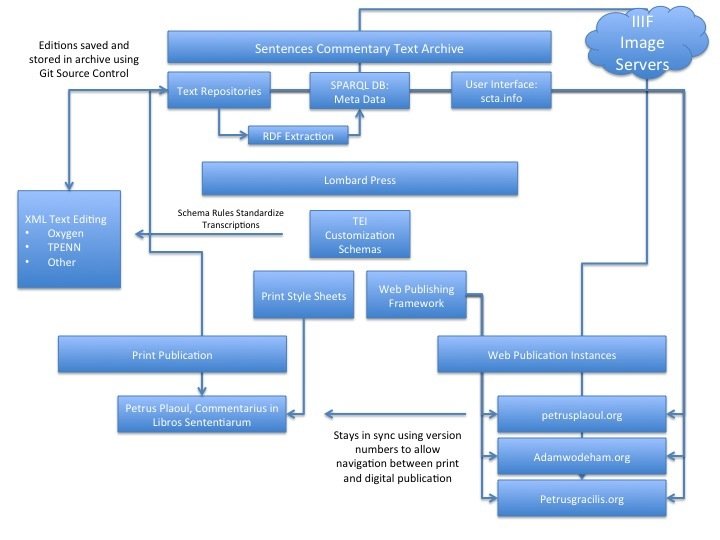
This database of metadata is built automatically by "crawling" the Semantically Encoded Editions that editors produce.
This database is public and open, which means anyone can build a web application on top of it.
This means that the text, the organizing database, and web publishing plaform are modular and separable.
In short: your data is not locked in one website. It can be used by multiple applications for a plurality of purposes.
Image Data: A data model to manage digital images of manuscripts
In order to create views where text and images can be immediately called upon and compared, a significant amount of abstraction and data-modeling is necessary.
We need to keep track of single digital files and their relationship to a "folio" or "page".
Further, we need to keep track of that folio's place within the "material hierarchy" (the codex) and the "content hierarchy" (the text).
Finally, we need to be able to track connections between our transcriptions of the text, folios, and by extension the digital images to which those transcriptions are related.
Consider the "text" of William Rothwell

The "text" has several "witnesses" or "manifestations"

Each of these "manifestations" has folios, which are digitally represented by at least one digital image, but sometimes several

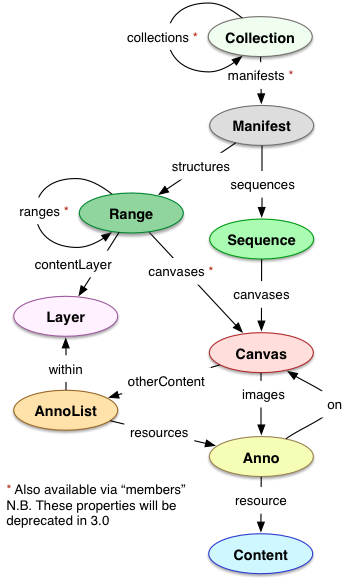
Enter IIIF: a community standard to help us organize and use images scattered throughout the world's libraries

Basic presentation model
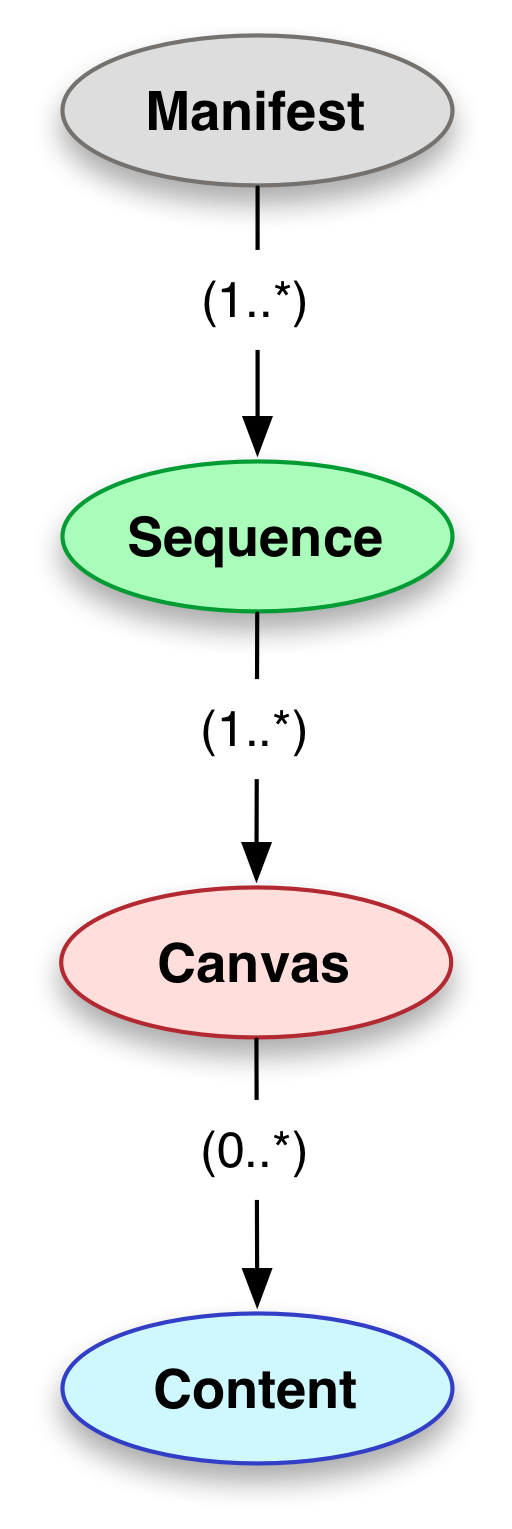
Extended presentation model