Creating an aggregated dataset from distributed sources - a report from the 2016 Basel meeting.
The following is a report and summary of the main proposal discussed at the “Linked Data and the Medieval Scholastic Tradition,” workshop held at the University of Basel in August 17-19, 2016.
The Problem Domain
The Basel workshop was attended by representatives of several separate research projects based in Europe dealing with some aspect of the medieval scholastic tradition. These projects ranged from Sentences commentaries to Aristotelian commentaries to logical texts and logical commentaries. Each group aims to create data and to display that data both in print and in various online formats.
The central problem we observed is that, because at present each group works fairly independently, each team has developed its own ‘silo’ of of 1) data input and creation, 2) data storage, and 3) data display.
There are couple of notable problems with this approach.
First, this requires each group to construct a technology stack, that despite various differences, conforms to a fairly standard pattern. This results in several redundant technology stacks that are expensive and difficult to maintain. For example, each group is developing some kind of a web form or data input interface. Most groups are then storing this data in a traditional relational mysql database. Finally, each group is then developing a web display that queries this database.
Second, because each group is developing this data pipeline on a single isolated server, their data is effectively isolated from the data of other related research groups. This causes two further problems. This isolation means that each group is in many cases producing highly redundant data. If a group needs a prosopographical data, they have no choice but to create their own prosopography, even if another group has already created a similar prosopography which they store on their own isolated server. Secondly, because each research group is dealing with a corner of a highly connected dataset, even when they are not producing redundant data, they are usually missing out on the opportunity to create and discover connections between their data and the data created by other groups.
Third and finally, because data creation interfaces, data storage, and data display interfaces are so tightly coupled, we are missing out on the opportunity to create re-usable interfaces and modular software. In other words, at the present, the ability to make a great display application, requires someone to also set up her own storage solution and to populate that database with her own data instead of simply being able to make a great display application using the data already being created by other groups.
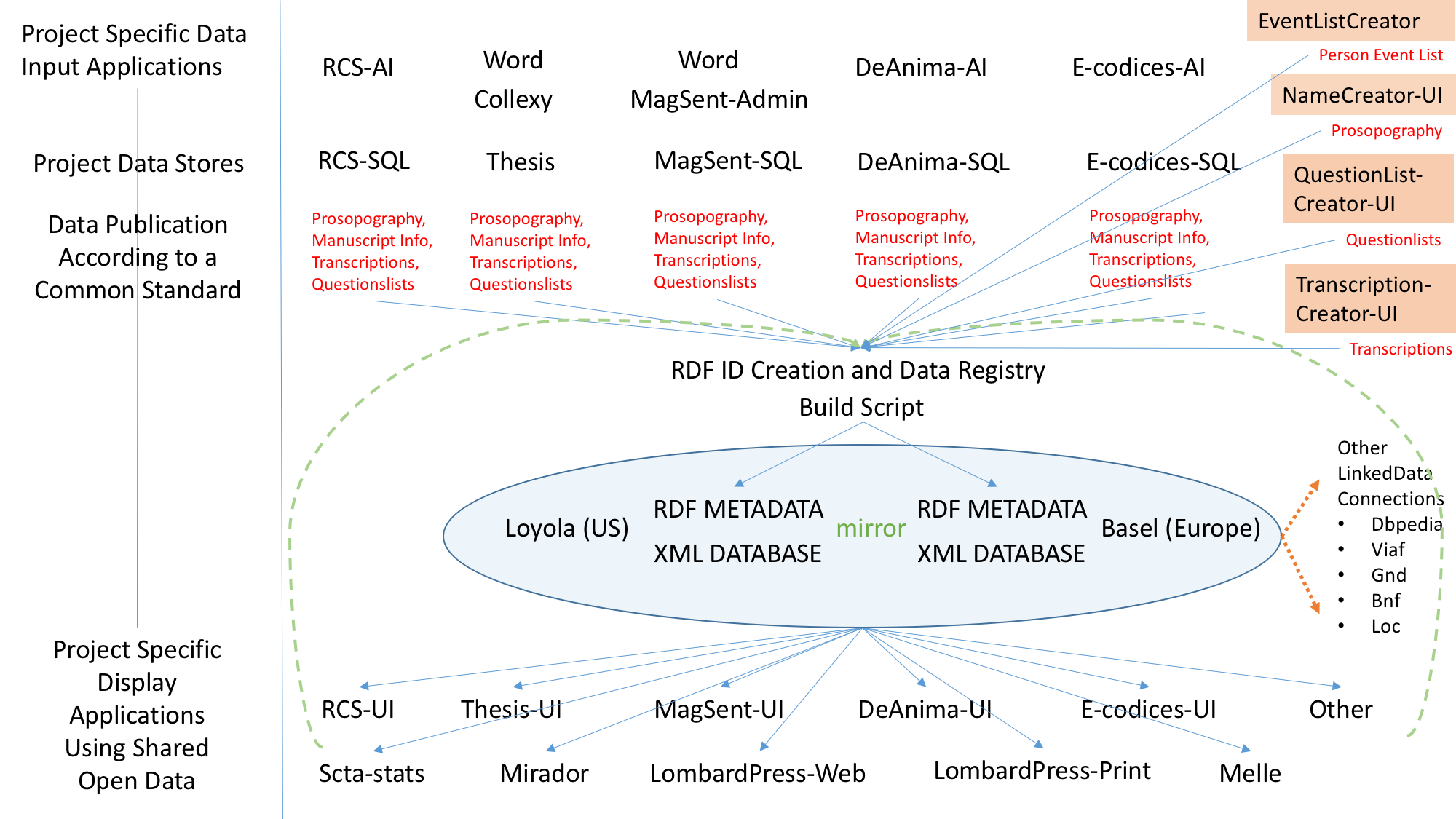
We have summarized the basic problem of data siloing in the following graphic.

A Proposal
The proposal presented at the Basel workshop aimed primarily at de-coupling the distinct tasks of data-creation, data-storage, and data-display, while still allowing individual projects complete autonomy with their own data.
The central proposal is to create RDF IDs for every common resource within our common problem domain, and then to allow independent research groups to publish the data they have about this common resource according to a common data standard, such as a customized TEI schema or Open Annotation.
Groups that want their information pooled into a common dataset simply need to register these “data feeds” with a common registry. Using this registry, we can write a “build-script” that crawls all known resources and constructs a RDF dataset. This build-script would harvests key pieces of information about common resources as well as links to individual project datasets and other global data sources such as DBPedia and VIAF. Further, beyond merely aggregating known information, the build-script can also infer new connections that no individual group knows in isolation, but can be deduced from two different pieces of information known by two previously isolated research groups. For example, if one groups knows that author X cites author Y, and another group knows that author Z cites author Y, the central dataset alone will know that author Y is cited both by authors X and Z. This third assertion is something that can only be inferred when these two pieces of information, originally isolated from one another are brought together.
This RDF meta data can then function as switch board for all display applications. Display applications can query directly to the public SPARQL endpoint for information about the location of encoded transcriptions or prosopographical information. In this way, we create a common pool of information from the work of each independent research group. Likewise, each display application is no longer limited to the information stored in the local data storage, but has access to the pool of information known by the entire collective.
The below graphic illustrates how the data silos seen above have been transformed into a web of criss-crossing connections.
Demonstration
During the course of the Basel workshop we constructed a couple of primitive examples to illustrate how this kind of distributed network of resources might work.
The RCS database has been collecting its own set of prosopographical data for authors of Sentences commentaries from which other related scholastic research projects could benefit. But up until now, this information has only been available in the RCS viewer which has localhost access to the RCS datastore.
In the proposed setup, the RCS project would be asked to publish a data feed as well as any other html data presentations it desired to present. These data feeds should be constructed according to a common standard such as the emerging Open Annotation standards. But for the present it was enough for RCS to simply publish its information in a simple XML feed. See below:
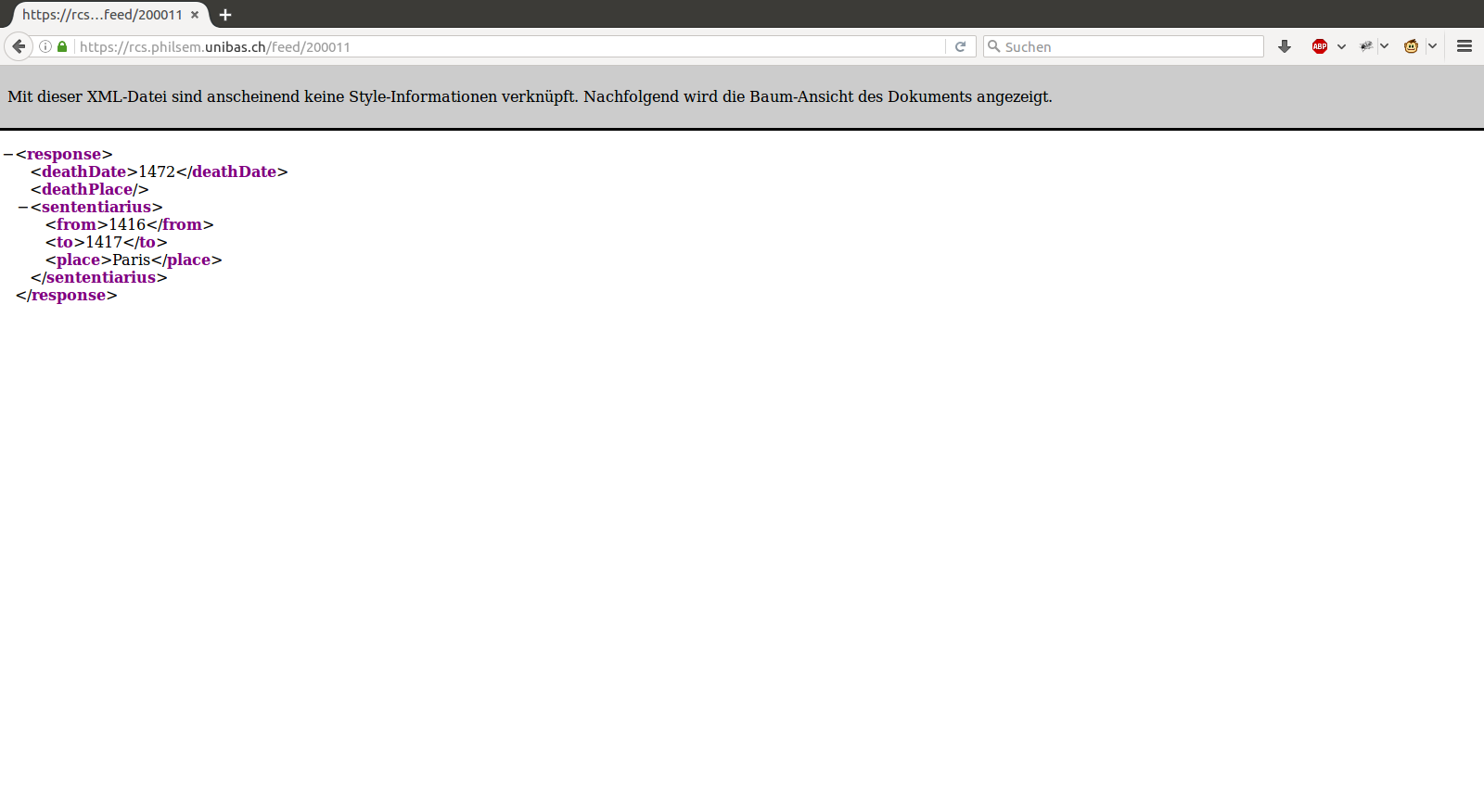
Once made available, we simply needed to register the address of this feed with SCTA build script, and all of this information becomes available to every other project via the SCTA RDF triple store. For example, here is the LombardPress display page for the author Herveus Natalis.

On the right you can see two different data feeds, one from the RCS database and one from Dbpedia. The LombardPress client does not have its own database, instead it queries the public SCTA RDF dataset for the information it needs. There it can find aggregated information about an individual author (such as the life events original recorded by the RCS team) or links to information about this author in other datasets (such as Dbpedia and the Dbpedia abstract).
If every research team begins to prioritize data publication as much as html or print publication, this kind of data sharing and re-use can become a reality on a large scale.
What’s more, each research group that contributes information (via an information feed) to the aggregated SCTA dataset can also get new information that enhances its own particular website or presentational output. For example, the RCS dataset is focused on name and manuscript identification. But another research group has focused on procuring lists of questions contained within Sentences commentaries. For example view, the question list below seen in the LombardPress viewer.
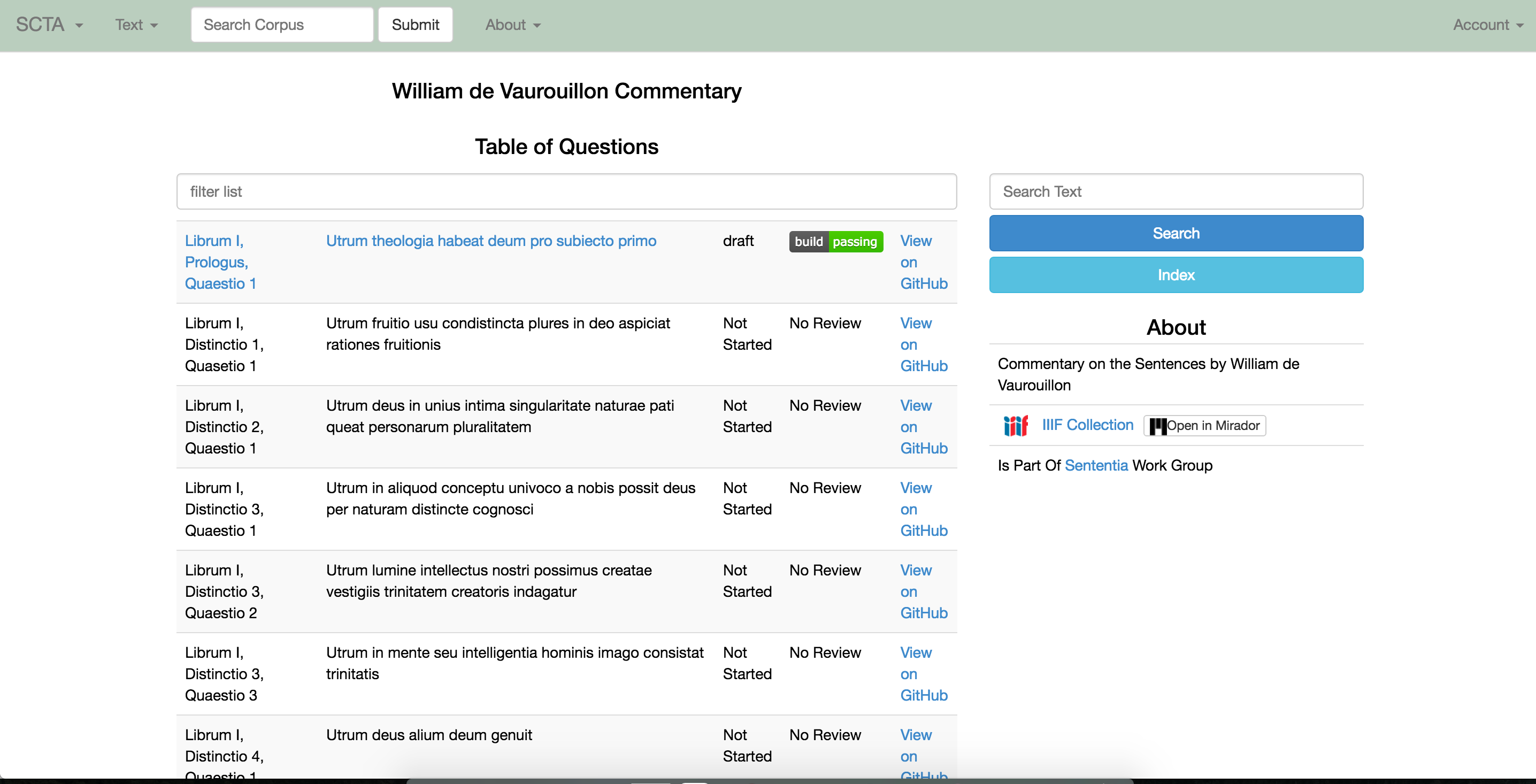
Once the SCTA RDF dataset has recorded the association between the SCTA RDF ID and the ids used in other datasets, the RCS data set can send a request for all of these question lists and display them in its own viewer without ever having to recreate this data in its own data store. In the example below, you can see the RCS viewer re-using this same information in its own display.
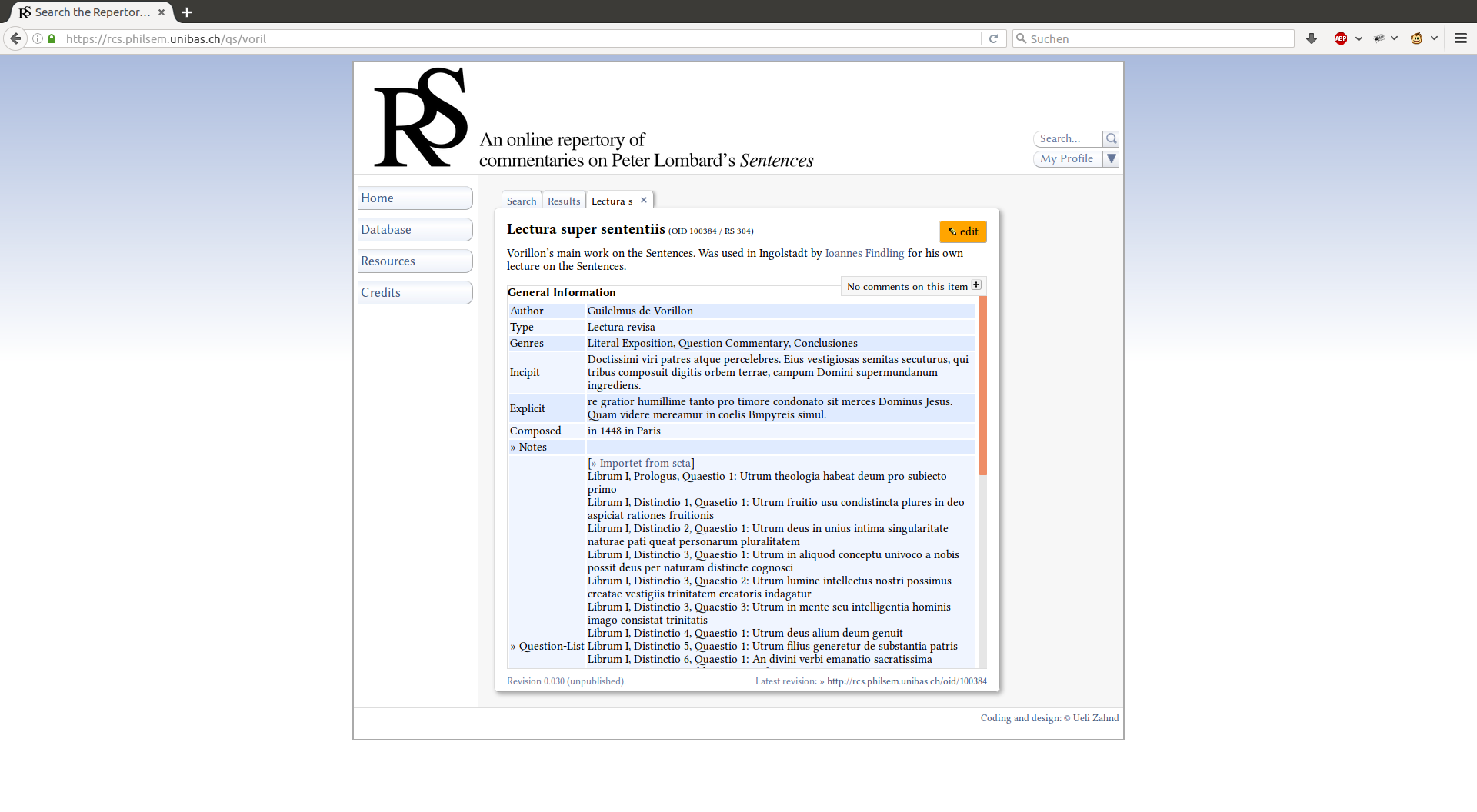
At this stage, this work is a proposal and work-in-progress. Therefore, we welcome and openly solicit comments and feedback. Do you have a related data set? We’d love to hear about it and think with your team about we can create an ever deeper connected distributed dataset.